Как найти использование дисков более 70% и отобразить в них самый большой файл
Я предполагаю, что вы хотели бы использовать этот необычный способ пометить фактический канал и teeв конце сообщения журнала, потому что вы не хотите, чтобы каждый канал echo?
Ну, можно и так:
logfile='report.txt'
log () {
if [ -z "$1" ]; then
cat
else
printf '%s\n' "$@"
fi | tee -a "$logfile"
}
log "some message"
log "some other message"
log "multi" "line" "output"
{
cat <<LETTER
Dear Sir,
It has come to my attention, that a whole slew of things may be
collected and sent to the same destination, just by using a single
pipe. Just use {... } | destination
Sincerely, $LOGNAME
LETTER
cat <<THE_PS
PS.
Here's the output of "ls -l":
THE_PS
ls -l
echo "LOL"
} | log
То есть оберните неуклюжую команду teeв простую функцию оболочки, имя которой легко ввести, и просто передайте ей вывод.
В этом примере функция logиспользует printfдля вывода данных, указанных в ее командной строке, или переключается на чтение из стандартного ввода, если это не были аргументы командной строки.
Можно даже использовать
./your_original_script_without_special_logging 2>&1 | log
Не сценарий оболочки,но baobab— очень полезный анализатор использования диска.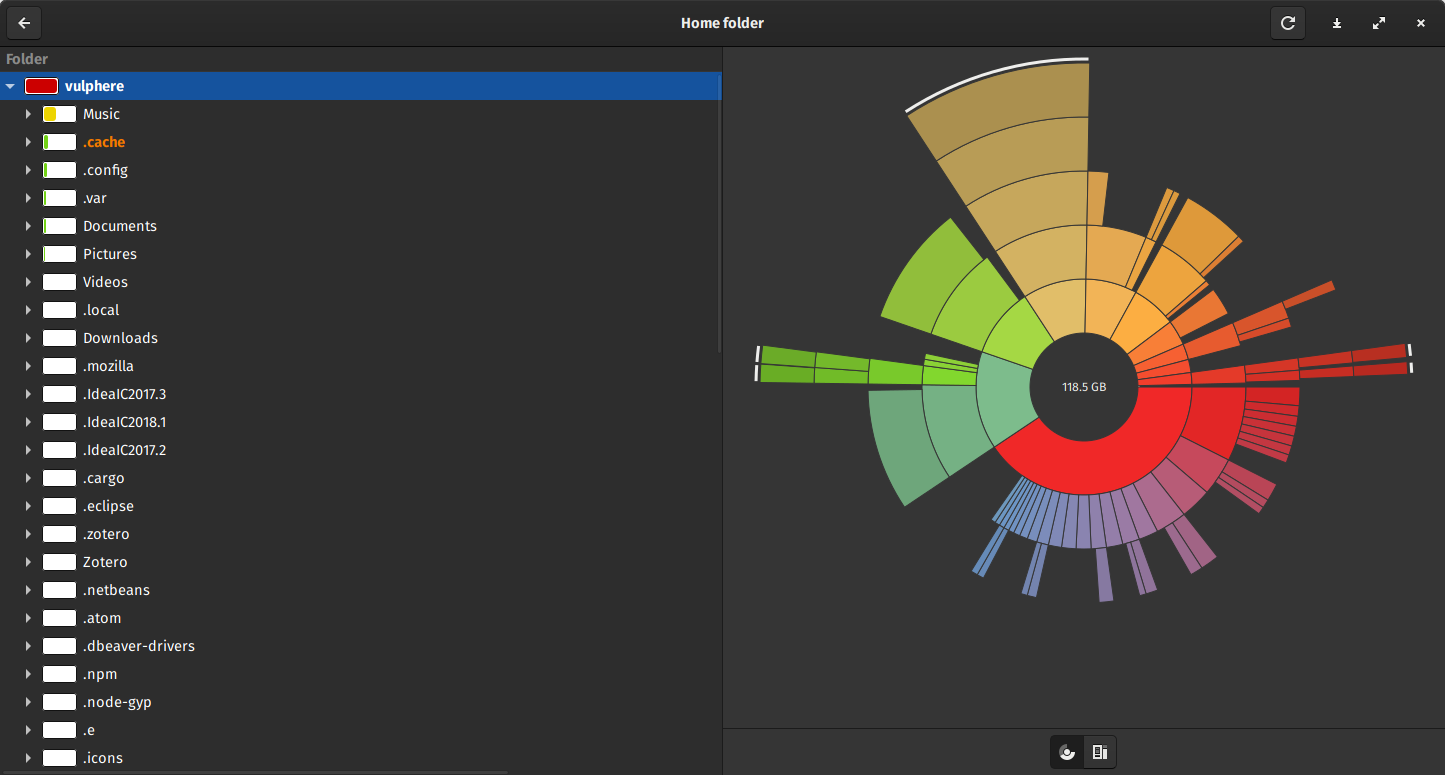
Введите baobabв командной строке, чтобы запустить его.
command1 :Отображает раздел с потреблением более 70 %
df -Ph| awk 'NR >1'| sed "s/%//g"| awk 'BEGIN {print "disk space issue exsists"}($(NF-1) > 70) {$(NF-1)=$(NF-1)"%";print $0}'
command2 отображает файл с наибольшим потреблением пространства раздела, занимающего больше места, чем 70
for i in `df -Ph| awk 'NR >1'| sed "s/%//g"| awk '($(NF-1) > 70) {$(NF-1)=$(NF-1)"%";print $NF}'`; do echo $i | awk -v i="$i" 'BEGIN{print "Below is the largestfile exists on partion"i}'; find $i -type f -printf "%s %p\n" 2>/dev/null| sort -k1 -nr | sed -n '1p'; echo "========================================";done